The benefits, risks, and considerations associated with using open-source LLMs, as well as the comparison with proprietary models.
Image is subject to copyright.
Large language models (LLMs) powered by artificial intelligence are gaining immense popularity, with over 325,000 models available on Hugging Face. As more models emerge, a key question is whether to use proprietary or open-source LLMs.
What are LLMs and How Do They Differ?LLMs leverage deep learning and massive datasets to generate human-like textProprietary LLMs are owned and controlled by a companyOpen-source LLMs are freely accessible for anyone to use and modifyProprietary models currently tend to be much larger in terms of parametersHowever, size isn’t everything – smaller open-source models are rapidly catching upCommunity contributions empower the evolution of open-source LLMs
How Do (LLM) Large Language Models Work? Explained
A large language model (LLM) is an AI system trained on extensive text data, designed to produce human-like and intelligent responses.

Benefits of Open Source LLMsTransparency – Better visibility into model architecture, training data, output generationCustomization through fine-tuning custom datasets for specific use casesCommunity contributions across diverse perspectives enable experimentationUse Cases
Open-source LLMs are being deployed across industries:
HealthcareDiagnostic assistanceTreatment optimizationFinanceApplications like FinGPT for financial analysisScienceModels like NASA’s trained on geospatial dataLeading Models on Hugging Face
The Hugging Face model leaderboard’s latest benchmarks.
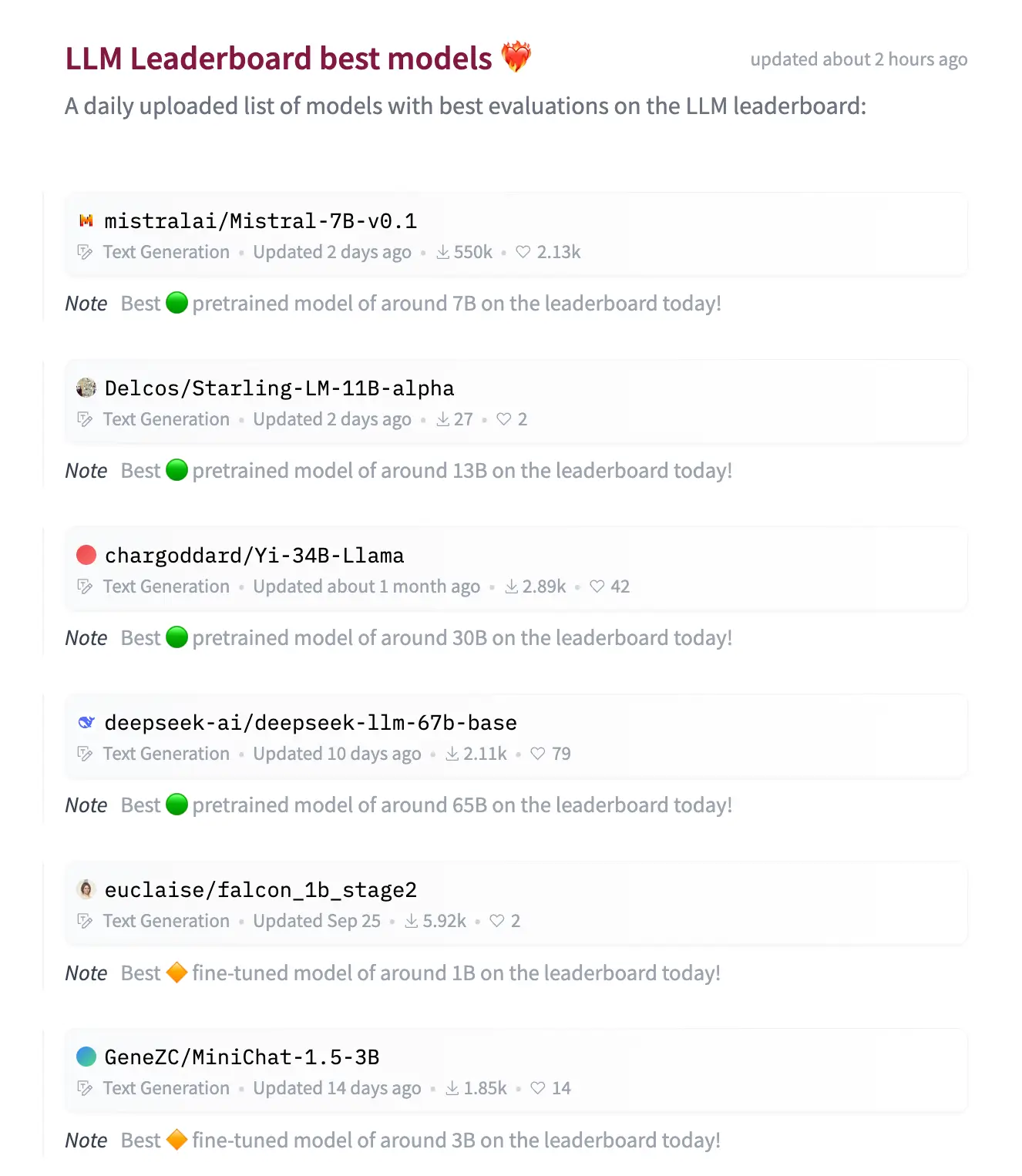 Top LLMs on Hugging Face
Top LLMs on Hugging Face
What is Vector Database and How does it work?
Vector databases are highly intriguing and offer numerous compelling applications, especially when it comes to providing extensive memory.
Downside of Open-source LLMs
Despite advances, LLMs have concerning have 3 major limitations:
Inaccuracy – Hallucinations from inaccurate/incomplete training dataSecurity – Potential exposure of private data in outputsBias – Embedding biases that skew outputs
Mitigating these risks in early-stage LLMs remains vital.
The Bottom Line
Open-source big language models make AI more available to everyone. This widens who can use them. But risks are still there. Even so, putting information out in the open and letting users adjust models to their needs gives power to people across fields.


